1. Install elasticsearch 2.3.4
Download elasticsearch 2.3.4mkdir /opt/setup
cd /opt/setup
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.4/elasticsearch-2.3.4.tar.gz
Unzip elasticsearch
mkdir -p /data/es-data
mkdir -p /opt/log/es-log
cd /opt/setup
tar xvfz elasticsearch-2.3.4.tar.gz
mv elasticsearch-2.3.4 /opt/
cd /opt/elasticsearch-2.3.4/conf
nano elasticsearch.ymlcluster.name: es-cluster
node.name: node-2.2
path.data: /data/es-data
path.logs: /opt/log/es-log
bootstrap.mlockall: true
network.host: 127.0.0.1,10.1.2.10
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.1.2.10", "10.1.2.11", "10.1.2.12"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 1
node.master: true
node.data: true
index.number_of_shards: 3
index.number_of_replicas: 2
script.groovy.sandbox.enabled: true
script.inline: true
script.indexed: true
threadpool.search.type: fixed
threadpool.search.size: 8
threadpool.search.queue_size: 8
threadpool.bulk.type: fixed
threadpool.bulk.size: 10
threadpool.bulk.queue_size: 10
threadpool.index.type: fixed
threadpool.index.size: 8
threadpool.index.queue_size: 10
indices.memory.index_buffer_size: 30%
indices.memory.min_shard_index_buffer_size: 12mb
indices.memory.min_index_buffer_size: 96mb
indices.fielddata.cache.size: 15%
indices.fielddata.cache.expire: 6h
indices.cache.filter.size: 15%
indices.cache.filter.expire: 6h
indices.recovery.max_bytes_per_sec: 100mb
index.refresh_interval: 30s
index.translog.flush_threshold_ops: 50000
http.compression: true
http.compression_level: 6
client.transport.ping_timeout: 20s
client.transport.nodes_sampler_interval: 20s
action.disable_close_all_indices: true
action.disable_delete_all_indices: true
action.disable_shutdown: trueCreate servicenano /etc/init.d/elasticsearch
#!/bin/sh
#
# /etc/init.d/elasticsearch -- startup script for Elasticsearch
#
# Written by Miquel van Smoorenburg <[email protected]>.
# Modified for Debian GNU/Linux by Ian Murdock <[email protected]>.
# Modified for Tomcat by Stefan Gybas <[email protected]>.
# Modified for Tomcat6 by Thierry Carrez <[email protected]>.
# Additional improvements by Jason Brittain <[email protected]>.
# Modified by Nicolas Huray for Elasticsearch <[email protected]>.
#
### BEGIN INIT INFO
# Provides: elasticsearch
# Required-Start: $network $remote_fs $named
# Required-Stop: $network $remote_fs $named
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Starts elasticsearch
# Description: Starts elasticsearch using start-stop-daemon
### END INIT INFO
PATH=/bin:/usr/bin:/sbin:/usr/sbin:/opt/jdk1.8.0_131/bin
NAME=elasticsearch
DESC="Elasticsearch Server"
DEFAULT=/etc/default/$NAME
if [ `id -u` -ne 0 ]; then
echo "You need root privileges to run this script"
exit 1
fi
. /lib/lsb/init-functions
if [ -r /etc/default/rcS ]; then
. /etc/default/rcS
fi
# The following variables can be overwritten in $DEFAULT
# Run Elasticsearch as this user ID and group ID
ES_USER=es
ES_GROUP=es
# Directory where the Elasticsearch binary distribution resides
ES_HOME=/opt/elasticsearch-2.3.4
# Heap size defaults to 256m min, 1g max
# Set ES_HEAP_SIZE to 50% of available RAM, but no more than 31g
ES_HEAP_SIZE=8g
# Heap new generation
#ES_HEAP_NEWSIZE=
# max direct memory
#ES_DIRECT_SIZE=
# Additional Java OPTS
#ES_JAVA_OPTS=
# Maximum number of open files
#MAX_OPEN_FILES=65535
MAX_OPEN_FILES=102400
# Maximum amount of locked memory
#MAX_LOCKED_MEMORY=
# Elasticsearch log directory
LOG_DIR=/opt/log/es-log
# Elasticsearch data directory
DATA_DIR=/data/es-data
# Elasticsearch configuration directory
CONF_DIR=/opt/elasticsearch-2.3.4/config
# Maximum number of VMA (Virtual Memory Areas) a process can own
MAX_MAP_COUNT=262144
# Path to the GC log file
#ES_GC_LOG_FILE=/opt/log/es-log/gc.log
ES_GC_LOG_FILE=$LOG_DIR/gc.log
# Elasticsearch PID file directory
PID_DIR="/var/run/elasticsearch"
# End of variables that can be overwritten in $DEFAULT
# overwrite settings from default file
if [ -f "$DEFAULT" ]; then
. "$DEFAULT"
fi
# CONF_FILE setting was removed
if [ ! -z "$CONF_FILE" ]; then
echo "CONF_FILE setting is no longer supported. elasticsearch.yml must be placed in the config directory and cannot be renamed."
exit 1
fi
# Define other required variables
PID_FILE="$PID_DIR/$NAME.pid"
DAEMON=$ES_HOME/bin/elasticsearch
DAEMON_OPTS="-d -p $PID_FILE --default.path.home=$ES_HOME --default.path.logs=$LOG_DIR --default.path.data=$DATA_DIR --default.path.conf=$CONF_DIR"
export ES_HEAP_SIZE
export ES_HEAP_NEWSIZE
export ES_DIRECT_SIZE
export ES_JAVA_OPTS
export ES_GC_LOG_FILE
export JAVA_HOME
export ES_INCLUDE
# Check DAEMON exists
test -x $DAEMON || exit 0
checkJava() {
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="$JAVA_HOME/bin/java"
else
JAVA=`which java`
fi
if [ ! -x "$JAVA" ]; then
echo "Could not find any executable java binary. Please install java in your PATH or set JAVA_HOME"
exit 1
fi
}
case "$1" in
start)
checkJava
if [ -n "$MAX_LOCKED_MEMORY" -a -z "$ES_HEAP_SIZE" ]; then
log_failure_msg "MAX_LOCKED_MEMORY is set - ES_HEAP_SIZE must also be set"
exit 1
fi
log_daemon_msg "Starting $DESC"
pid=`pidofproc -p $PID_FILE elasticsearch`
if [ -n "$pid" ] ; then
log_begin_msg "Already running."
log_end_msg 0
exit 0
fi
# Prepare environment
mkdir -p "$LOG_DIR" "$DATA_DIR" && chown "$ES_USER":"$ES_GROUP" "$LOG_DIR" "$DATA_DIR"
# Ensure that the PID_DIR exists (it is cleaned at OS startup time)
if [ -n "$PID_DIR" ] && [ ! -e "$PID_DIR" ]; then
mkdir -p "$PID_DIR" && chown "$ES_USER":"$ES_GROUP" "$PID_DIR"
fi
if [ -n "$PID_FILE" ] && [ ! -e "$PID_FILE" ]; then
touch "$PID_FILE" && chown "$ES_USER":"$ES_GROUP" "$PID_FILE"
fi
if [ -n "$MAX_OPEN_FILES" ]; then
ulimit -n $MAX_OPEN_FILES
fi
if [ -n "$MAX_LOCKED_MEMORY" ]; then
ulimit -l $MAX_LOCKED_MEMORY
fi
if [ -n "$MAX_MAP_COUNT" -a -f /proc/sys/vm/max_map_count ]; then
sysctl -q -w vm.max_map_count=$MAX_MAP_COUNT
fi
# Start Daemon
start-stop-daemon -d $ES_HOME --start -b --user "$ES_USER" -c "$ES_USER" --pidfile "$PID_FILE" --exec $DAEMON -- $DAEMON_OPTS
return=$?
if [ $return -eq 0 ]; then
i=0
timeout=10
# Wait for the process to be properly started before exiting
until { kill -0 `cat "$PID_FILE"`; } >/dev/null 2>&1
do
sleep 1
i=$(($i + 1))
if [ $i -gt $timeout ]; then
log_end_msg 1
exit 1
fi
done
fi
log_end_msg $return
exit $return
;;
stop)
log_daemon_msg "Stopping $DESC"
if [ -f "$PID_FILE" ]; then
start-stop-daemon --stop --pidfile "$PID_FILE" \
--user "$ES_USER" \
--quiet \
--retry forever/TERM/20 > /dev/null
if [ $? -eq 1 ]; then
log_progress_msg "$DESC is not running but pid file exists, cleaning up"
elif [ $? -eq 3 ]; then
PID="`cat $PID_FILE`"
log_failure_msg "Failed to stop $DESC (pid $PID)"
exit 1
fi
rm -f "$PID_FILE"
else
log_progress_msg "(not running)"
fi
log_end_msg 0
;;
status)
status_of_proc -p $PID_FILE elasticsearch elasticsearch && exit 0 || exit $?
;;
restart|force-reload)
if [ -f "$PID_FILE" ]; then
$0 stop
sleep 1
fi
$0 start
;;
*)
log_success_msg "Usage: $0 {start|stop|restart|force-reload|status}"
exit 1
;;
esac
exit 0chmod +x /etc/init.d/elasticsearch
update-rc.d elasticsearch defaults
update-rc.d elasticsearch enableTạo user và phân quyền
groupadd es
useradd -r -M -d /opt/elasticsearch-2.3.4 -s /bin/bash es
passwd es (Đặt password phức tạp)
chown -R es:es /opt/elasticsearch-2.3.4/config
chown -R es:es /db/es-data
chown -R es:es /opt/log/es-logSet limit openfile
nano /etc/security/limits.conf
# allow user 'es' mlockall
es soft memlock unlimited
es hard memlock unlimited
nano /etc/sysctl.conf
vm.max_map_count=262144
sysctl -pEdit profile
nano /etc/profile
ELASTICSEARCH HOME:
ES_HOME=/opt/elasticsearch-2.3.4
export ES_HOME
source /etc/profileInstall elasticsearch-head
cd /opt/elasticsearch
bin/plugin install mobz/elasticsearch-head2. Import data from sqlserver to elasticsearch
# cd /opt/setup
wget https://github.com/jprante/elasticsearch-jdbc/archive/2.3.4.1.zip
Edit /etc/profile
#JDBC_IMPORTER_HOME:
JDBC_IMPORTER_HOME=/opt/elasticsearch-jdbc-2.3.4.1
export JDBC_IMPORTER_HOME
PATH=$PATH:$JDBC_IMPORTER_HOME/bin:$ES_HOME/bincd /opt
unzip setup/2.3.4.1.zip
mv /opt/2.3.4.1 /opt/elasticsearch-jdbc-2.3.4.1Tạo mapping cho index mapping.json
{
"settings":{
"index":{
"number_of_shards":"3",
"number_of_replicas":"0",
"max_result_window":"500000",
"analysis":{
"filter":{
"autocomplete_filter":{
"type":"edge_ngram",
"min_gram":"1",
"max_gram":"50"
}
},
"analyzer":{
"autocomplete":{
"filter":[
"lowercase",
"autocomplete_filter"
],
"type":"custom",
"tokenizer":"standard"
},
"html_content":{
"filter":[
"standard",
"lowercase",
"asciifolding"
],
"char_filter":[
"html_strip"
],
"tokenizer":"standard"
}
}
}
}
},
"mappings":{
"product_publish":{
"properties":{
"textsearch":{
"analyzer":"autocomplete",
"type":"string"
}
}
}
}
}mapping.sh
#!/bin/bash
PATH_INDEX=/opt/script/es-script/phil.com/auto-phil
source $PATH_INDEX/variable.txt
curl -XPUT "http://127.0.0.1:9200/$index_auto" \
-H 'Content-Type: application/json' \
-d@$PATH_INDEX/mapping.jsonScript import data
cat /opt/script/es-script/phil.com/variable.txt
JAVA_HOME=/opt/jdk1.8.0_131
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin
ES_HOME=/opt/elasticsearch-2.3.4
LOG_FILE=/opt/log/es-log/phil/importer-day-phil.log
PATH_INDEX=/opt/script/es-script/phil/auto-phil
JDBC_IMPORTER_HOME=/opt/elasticsearch-jdbc-2.3.4.1
bin=$JDBC_IMPORTER_HOME/bin
lib=$JDBC_IMPORTER_HOME/lib
cluster=es-cluster
host=127.0.0.1
port=9300
user=user_service
password=C1-A0-94
server=10.1.2.20:5432
database=phil_db
index_auto=phil_2025
type_auto=product_publishcat /opt/script/es-script/phil.com/import/import-db-product.sql
SELECT tmp.*, pc.fullname, pc.phone, pc.email, pc.address
FROM
(
SELECT
p.productid As _id,
p.productid,
p.title,
coalesce(NULLIF(P.image, ''), NULL) as image,
p.textsearch,
p.region,
p.city,
p.maker,
p.model,
p.version,
p.year,
p.secondhand,
p.type,
p.transmissionid,
p.color,
p.numofkm,
p.numofkmunit,
p.price,
p.haveprice,
p.downpayment,
p.allowoffers,
p.paymenttype,
p.registration,
p.platenumber,
p.createduser,
p.usertype,
p.sold,
coalesce(p.viptype, 0) as viptype,
p.status,
p.ispublish,
p.startdate,
p.enddate,
p.publishdate,
p.lastuptimespan,
p.lastuptime,
p.createdate,
coalesce(NULLIF(p.image, ''), NULL) as image,
p.videourl,
p.textsearch,
p.lastupdateddate
FROM Product p
WHERE P.lastupdateddate >= (now()-interval'2 days')
ORDER BY P.publishdate DESC
) AS tmp
INNER JOIN productcontact pc ON pc.productid = tmp.productid;cat /opt/script/es-script/phil.com/import/import-db-product.sh
#!/bin/bash
PATH_INDEX=/opt/script/es-script/phil.com
source $PATH_INDEX/variable.txt
echo '{
"type" : "jdbc",
"jdbc": {
"elasticsearch" : {
"cluster" : "'$cluster'",
"autodiscover" : false,
"host" : "'$host'",
"port" : "'$port'"
},
"url" : "jdbc:postgresql://'$server'/'$database'",
"user" : "'$user'",
"password" : "'$password'",
"timezone" : "GMT+8",
"sql":"'$PATH_INDEX'/import-days/import-db-product-publish.sql",
"index" : "'$index_auto'",
"type" : "'$type_auto'"
}
}' | java \
-cp "${lib}/*" \
-Dlog4j.configurationFile=${PATH_INDEX}/log4j2.xml \
org.xbib.tools.Runner \
org.xbib.tools.JDBCImporterTạo lịch để định kỳ import dữ liệu
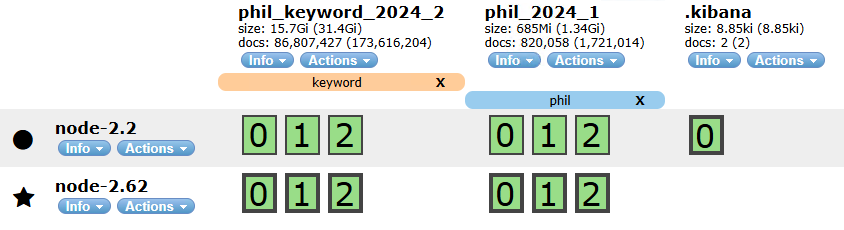
crontab -l
*/1 * * * * /opt/script/es-script/phil.com/import/import-db-product.shKết quả sau khi import